Polynomial Smooth Minimum
TL;DR: Live shader here
Motivation
Iñigo Quilez, hallowed be his name, wrote a function for blending distance function primitives to model organic shapes with raymarching. (for introduction to raymarching, see the article I wrote here
He wrote a very nice article about it here
It's a foundational technique to get natural looking implicit surfaces which is important because nature is smooth and continuous(… that's at least what they told me in school anyway) and a simple union of two shapes is not.
The first time you see something it's a trick, the second time it's a technique
For anyone that is trying to learn this stuff and for whom it's still a trick, hopefully this is helpful. I know I can only reluctantly use some derived result if I don't understand where it's coming from.
It was impossible to follow iq's derivation in his article, surely the material is just so obvious to him that the terseness with which his derivation was written wasn't intentional. In my opinion, especially for the beginner like me, derivations are not the place for compactness, especially for something so foundational.
It really gave me pause to see a couple really smart guys I follow using this function without fulling understanding it or deriving it correctly. See: Sebastian Lague and The Art of Code Both are far more productive, experienced and knowledgable than me, so maybe the real takeaway of this derivation is to choose my battles more wisely. There is however something deeply fruitful about reinventing the wheel, despite the undeniable loss in productivity.
Derivation
Looking at iq's article, the example of the polynomial smin seems to be getting a smooth minimum between some decreasing exponential and a sinusoid. That seems a little hard to think about right now with it's many intersection points to account for, so let's just look at a decreasing exponential with one intersection
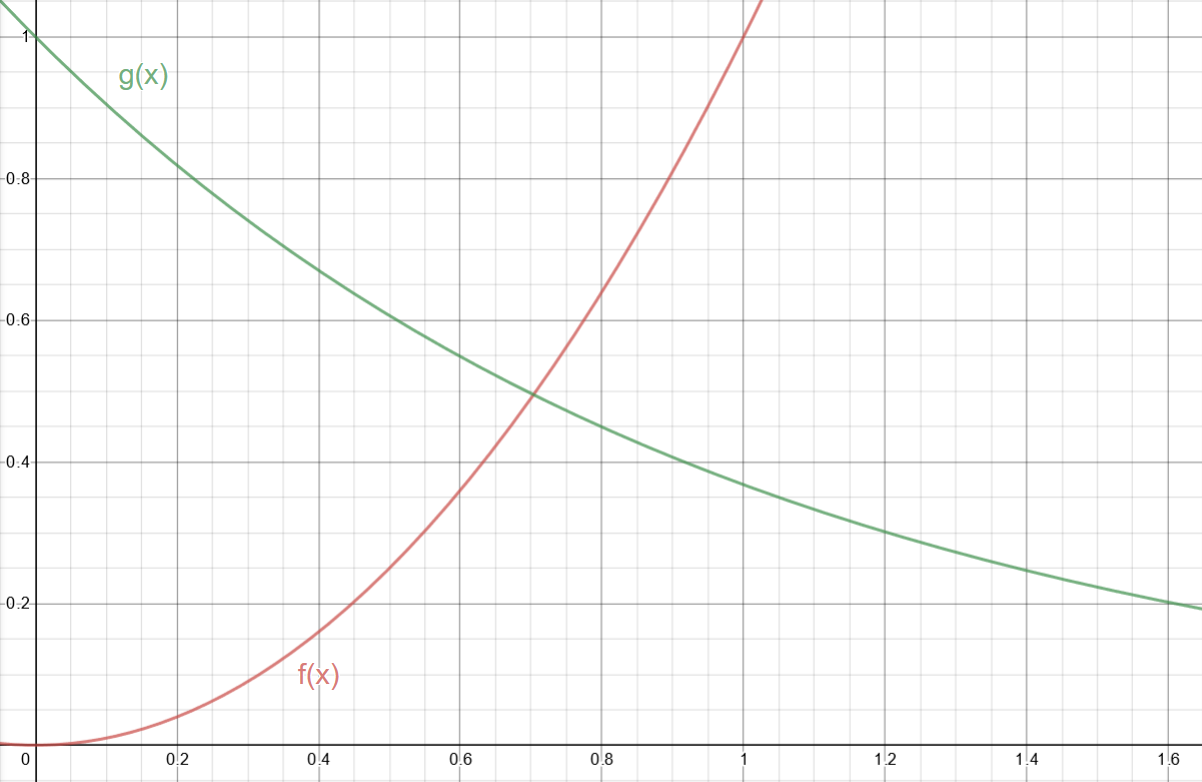
Figure 1: Our functions; \(f(x) = x^2\) and \(g(x) = e^{-x}\)
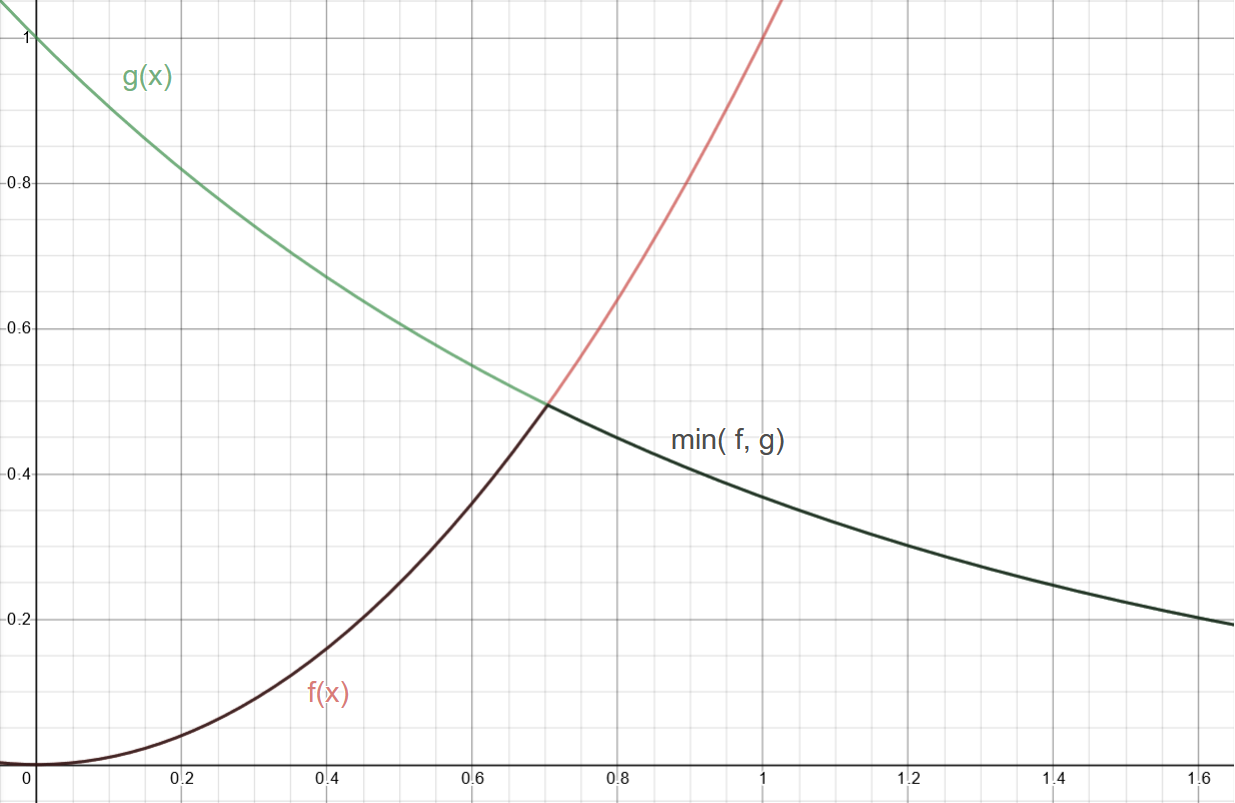
Figure 2: The simple union of our two functions
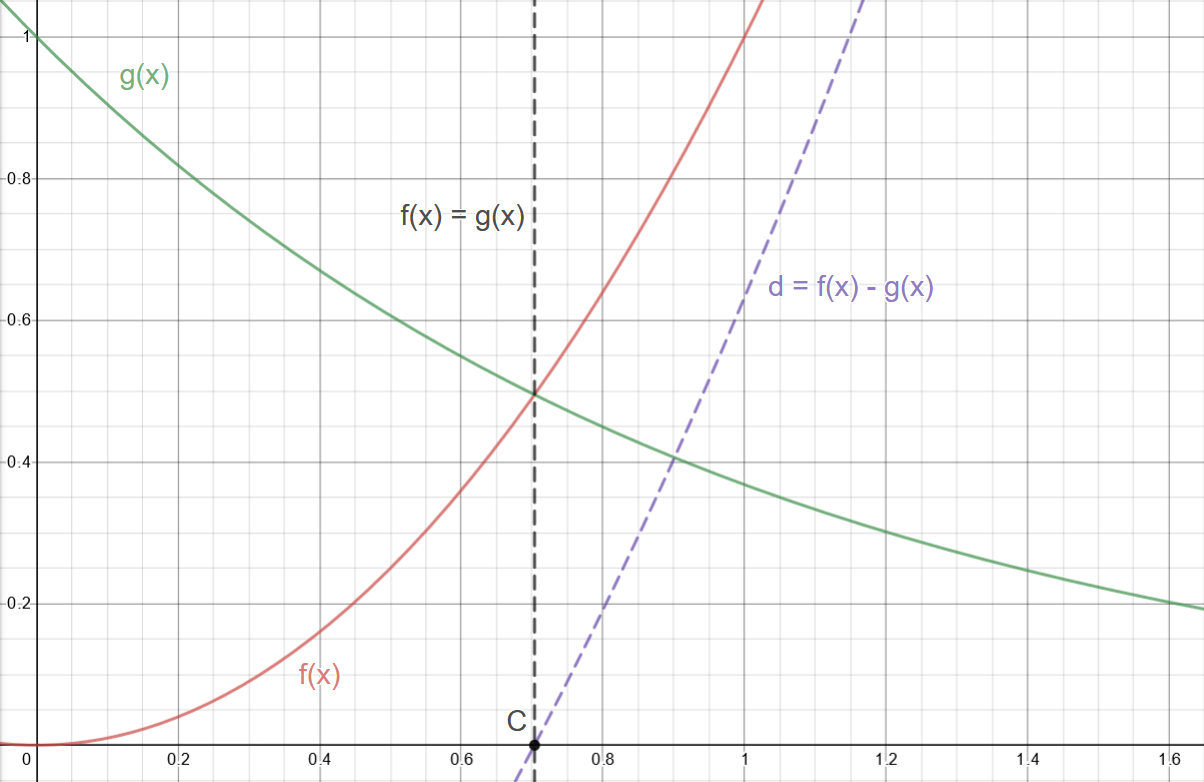
Figure 3: Our functions with their difference \(d = f(x) - g(x)\)
Looking at this hard minimum, we can imagine a smooth curve in its place that connects \(f\) and \(g\) when the functions are sufficiently close to their intersection. But what does sufficiently close mean more precisely, \(i.e\) where should the constructed function stop being \(f\) and start being \(g\)?
Now for a reasonably useless aside:
At first blush, it's not obvious to me how to make a meaningful relationship or constraint between the two functions beyond that they're equal to each other at their intersection. This gives us a point \(C\), \(d = 0\) and its mapping \(x\) value
Looking at a given \(\epsilon\) neighborhood around this point, you can see that \(d\) must be on the interval \([d(x-\epsilon), d(x+\epsilon)]\) which are small, not necessarily identical values.
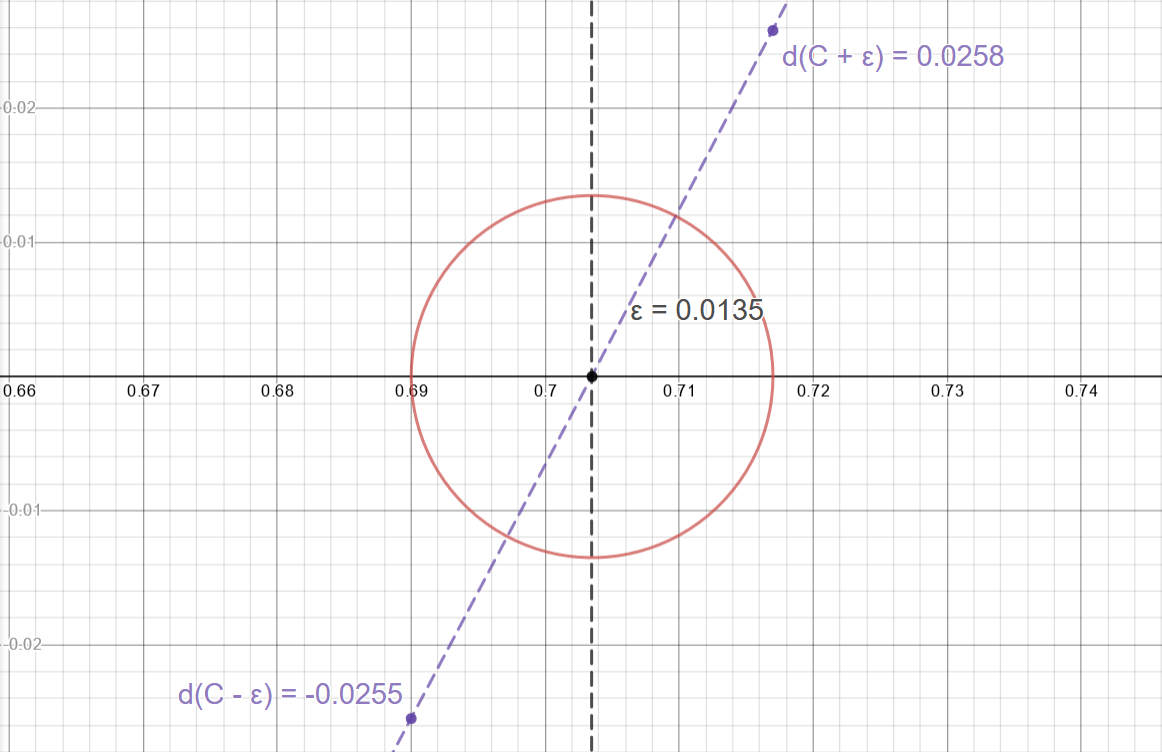
Well, now we're at loss about how to generalize along this line of thinking.
And it gets worse, talking about points close to where a root of a function is requires us to know where the root is in the first place. This is a non trivial thing and a whole numerical method in its own right. And even worse… iq's original diagram was of some flavor of a sinusoid and its intersection with a decreasing exponential has infinitely many roots. We're noping on out of here my friend, it's just too messy; we'll need to think of another relationship characteristic of proximity to the intersection.
A helpful observation is to note that this \(\epsilon\) could be made arbitrarily small, small enough to where \([d(x-\epsilon), d(x+\epsilon)]\) is smaller than our original epsilon.
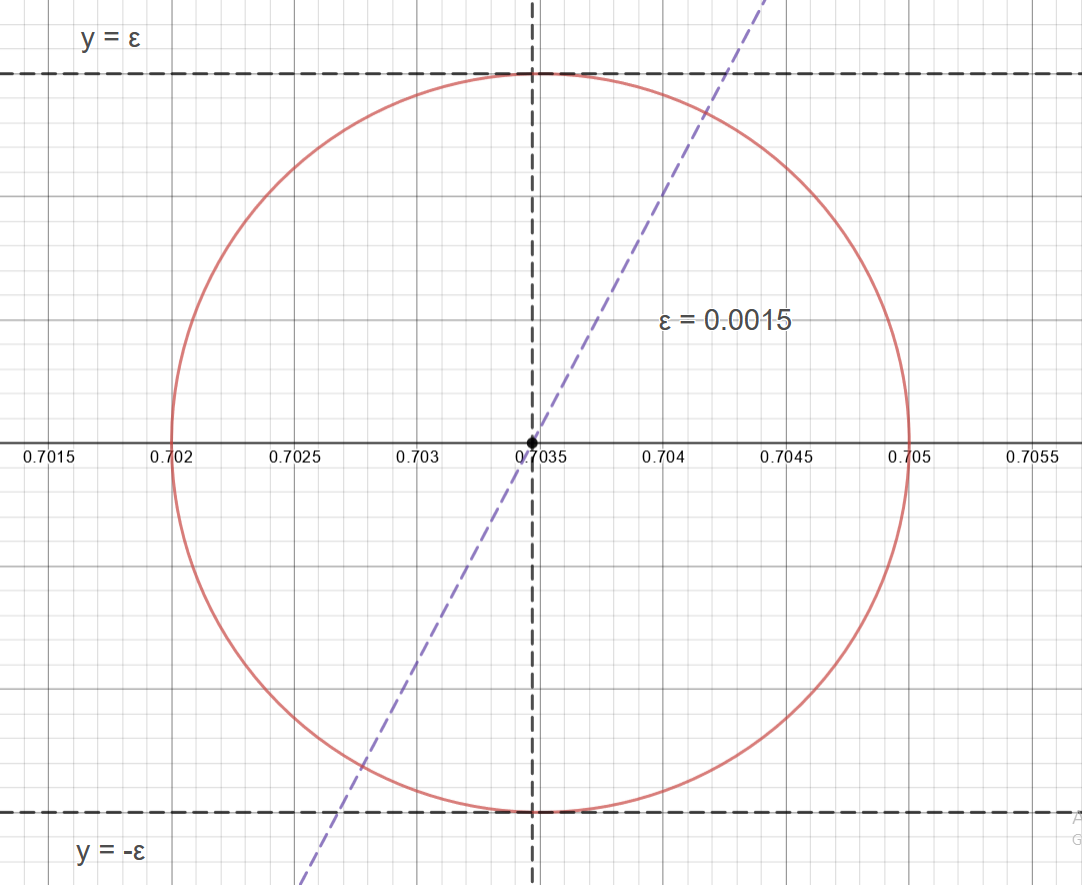
It's also helpful to note that the difference between two polynomials is also a polynomial and that polynomials are continuous everywhere. So, by the intermediate value theorem, for some small value say \(k\), \(d\in [-k, k]\).
"Sufficiently close" to an intersection then could be recast in terms of the difference's value instead of being near its root.
Note however that \(d\) reaches \(-k\) and \(k\) at different rates, however slightly different, as discussed previously and if we are planning on using this interval as our generalized way to talk about being close to the intersection our choice of \(k\) will affect how the curve stiches to its base functions. In the limit close to \(C\) this doesnt matter, but for medium sized choices of \(k\) I think you could play around with how \(k\) changes before and after \(C\) to get something more uniform or weird as you fancy.
Well, this is much nicer: we don't need to know anything about the \(x\) value for a mapped zero and it's just one value, some chosen \(k\).
Now that we at least have a general method of talking about being close to an intersection. (My god, We're only on the second line of iq's derivation…) What should the curve be in that interval? I'm not sure there's an intelligent reason for choosing linear interpolation over something more exotic looking besides that linear interpolation is familiar and more importantly meets our first constraint for our constructed curve/ spline thingy, namely it must be \(f\) at the beginning of "being close to the intersection” (\(i.e\) at \(d = -k\)) and \(g\) at the end of "being close to the intersection” (\(i.e\) at \(d = k\)).
Linear interpolation: <br> \(\xi = (1 - u)f + ug\) ; \(u \in [0, 1]\) <br> So when \(u = 0, \xi = f\) and \(u = 0, \xi = g\)
But we're not necessarily working on the interval \([0, 1]\) Thus we have to map our chosen "closeness" interval \([-k, k]\) to \([0, 1]\)
Like the choice of linear interpolation, linear mapping seems easiest/ most familar:
\(\ell = mx + b\) With boundary conditions: \(\ell(-k) = 0\) and \(\ell(k) = 1\) \(\ell(-k) = -mk + b = 0, \implies b = mk\) \(\ell(k) = mk + mk = 2mk = 1 \implies m = \frac{1}{2k}\) \(\implies b = \frac{1}{2}\) \(\implies \ell = \frac{x}{2k} + \frac{1}{2}\)
but we're interpolating over the difference, not \(x\)
\[\ell = \frac{d}{2k} + \frac{1}{2}\]
also, we don't want to include values outside the "sufficiently close" interval \(\implies\) we don't want to include the values when \(\ell < 0\) and \(\ell > 1\)
\(\implies \ell =\) max(0, min(\(1\), \(\ell\)), note that this is the same as the glsl hardware accelerated function clamp;
in glsl: \(\ell =\) clamp(\(\ell\), \(0\), \(1\))
Just using a linear interpolation between our functions with the correctly mapped interval gives us a pretty good result: \(\xi = (1-\ell)f + \ellg\); \(\ell = d / {2k} + 1/2\) and \(k \approx 0.1\)
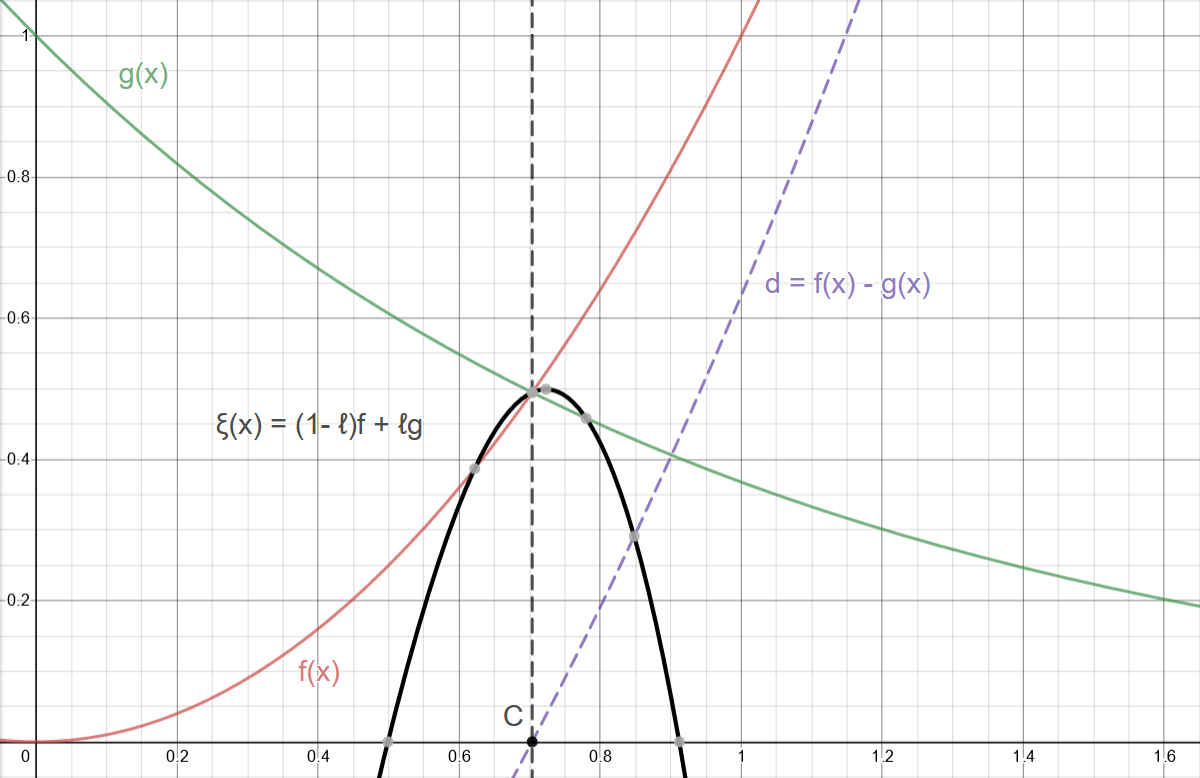
Figure 4: As expected, our interpolated curve is equal to \(f\) and \(g\) when \(d = -k\) and \(d = k\) respectively.
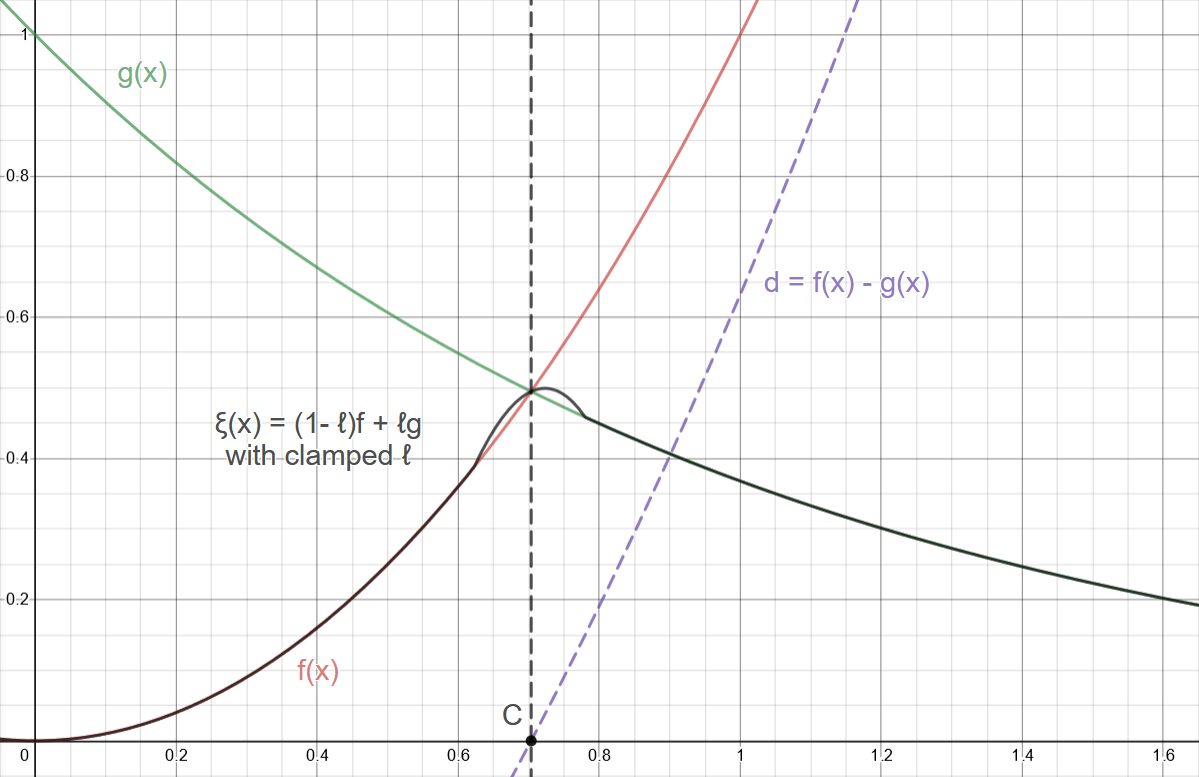
Figure 5: This is improved by limiting our ℓ value to only ever be between \(0\) and \(1\) as reasoned before
What now and how do we improve on this? Well, before we go racking our brains for something more creative, what other constraints exist for our curve? Not only must ξ evaluate to \(f\) & \(g\) at the "closeness" interval boundaries, but since it's supposed to be smooth, its derivative must also match the boundaries' derivatives. So what is ξ's derivative?
\[\xi = \left( 1 - \ell \right) f + \ell g\]
by the product rule:
\[\frac{d\xi}{dx} = \frac{d(1-\ell)}{dx}f + \frac{df}{dx}(1-\ell) + \frac{d\ell}{dx}g + \frac{dg}{dx}\ell\]
\[\frac{d\xi}{dx} = \frac{-d\ell)}{dx}f + \frac{df}{dx} - \ell\frac{df}{dx} + \frac{d\ell}{dx}g + \frac{dg}{dx}\ell\]
collecting like terms:
\[\frac{d\xi}{dx} = (g - f)\frac{d\ell)}{dx} + (1 - \ell)\frac{df}{dx} + \frac{dg}{dx}\ell\]
Note that \(g - f\) is just \(-d\)
Testing our first boundary: \(d = -k \implies l = 0, g - f = k\)
Again \[\xi = \left( 1- \ell \right) f + \ell g, l = 0 \implies g = 0\]
\[\frac{d\xi}{dx} = k\frac{d\ell)}{dx} + \frac{df}{dx}\]
We require ξ's derivative to equal the derivative of \(f\) at this boundary in order to be smooth.
Thus we must subtract this extra, first term from our original expression for ξ's derivative to match.
\[\implies \frac{d\xi}{dx} = (g - f)\frac{d\ell)}{dx} + (1 - \ell)\frac{df}{dx} + \frac{dg}{dx}\ell - k\frac{d\ell)}{dx}\]
Similarly, evaluating ξ's derivative at the other boundary:
\(d = k \implies l = 1, g - f = -k\) \[\implies \frac{d\xi}{dx} = (-k)\frac{d\ell)}{dx} + (0)\frac{df}{dx} + \frac{dg}{dx}\ell - k\frac{d\ell)}{dx}\] \[\implies \frac{d\xi}{dx} = (-2k)\frac{d\ell)}{dx} + \frac{dg}{dx}\ell\]
Again we require ξ's derivative to equal the derivative of \(f\) at this boundary for smoothness.
So we must now add this extra term to our expression for ξ's derivative to match
\[\implies \frac{d\xi}{dx} = (g - f)\frac{d\ell)}{dx} + (1 - \ell)\frac{df}{dx} + \frac{dg}{dx}\ell - k\frac{d\ell)}{dx} +2k\frac{d\ell)}{dx}\]
But now we're a bit stuck… after all, doesn't adding this term change what the ξ's derivative will evaluate to at the first boundary? Definitely, and if we were to go back and redo our process we'd be stuck in a vicious cirlce; so we need to have this second boundary corrective term disappear at the first boundary, but still be around at the second boundary.
We're in luck though; just such a term exists and has already been used by us, namely, ℓ. \(\ell\) by design is just such a term, so if we multiply this corrective term by ℓ, it will do precisely what we want it to.
\[\implies \frac{d\xi}{dx} = (g - f)\frac{d\ell)}{dx} + (1 - \ell)\frac{df}{dx} + \frac{dg}{dx}\ell - k\frac{d\ell)}{dx} +2k\ell\frac{d\ell)}{dx}\]
Whew, that already feels like clever enough work to stop, but we want the function, not its derivative. So how to integrate this thing?
\[\xi = \int_{}^{} (g - f)\frac{d\ell)}{dx} + (1 - \ell)\frac{df}{dx} + \frac{dg}{dx}\ell - k\frac{d\ell)}{dx} +2k\ell\frac{d\ell)}{dx} dx\]
Regrouping terms to make the underlying product rule more obvious.
\[\xi = \int_{}^{} g\frac{d\ell)}{dx} - f\frac{d\ell)}{dx} + \frac{df}{dx} - \ell\frac{df}{dx} + \frac{dg}{dx}\ell - k\frac{d\ell)}{dx} +2k\ell\frac{d\ell)}{dx} dx\]
\[\xi = \int_{}^{} g\frac{d\ell)}{dx} + \frac{dg}{dx}\ell - \left(f\frac{d\ell)}{dx} + \ell\frac{df}{dx}\right) + \frac{df}{dx} - k\frac{d\ell)}{dx} +2k\ell\frac{d\ell)}{dx} dx\]
reversing the product rule on the first two terms or integrating by parts and integrating the last three, straightforward integrals
\[\xi = g\ell - f\ell + f - k\ell + k\ell^2\]
\[\implies \xi = \left( 1 - \ell \right) f + \ell g - k \ell \left( 1 - \ell \right)\]
This is exactly iq's function ( mix is glsl hardware accelerated linear interpolation)
// polynomial smooth min (k = 0.1); float smin( float a, float b, float k ) { float h = clamp( 0.5+0.5*(b-a)/k, 0.0, 1.0 ); return mix( b, a, h ) - k*h*(1.0-h); }
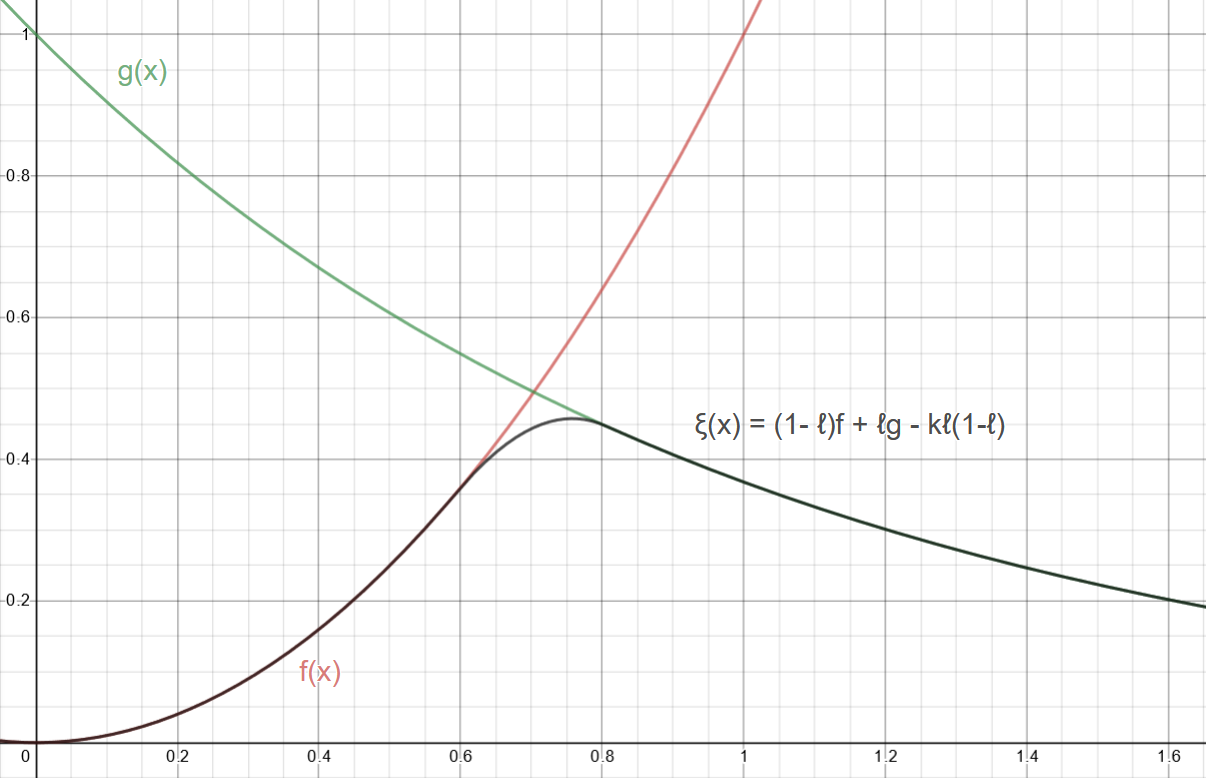
Figure 6: Our smooth minimum
Wrapping Up:
This was a little dive into shader flavored spline interpolation; we took a nice result from an authoritative source and rederived it from first principles. The function itself, as said by iq, is only \(C^1\) continous, but we could extend this with our same approach to be whatever order continuous we like at the expense of performance. Shaders are performance sensitive and the first order polynomial smin is what you mostly see perusing shadertoy.
Live shader can be found here
If you're curious how I made this shader, the big picture is that I'm using the "over operator" to make a graph of functions which is a really common technique, see this well known resource for more on that. Additionally, I am using a handmade easing function that is interpolating over the functions' derivatives' values to make the lines more uniform with some functional conditionals to help out.
Hopefully it's helped someone besides me. Thank you for reading.
Annex
Shader Source
#define SCALE (2.) #define PI (3.14159) float when_gt(float x, float y) { return max(sign(x - y), 0.0); } float graph(float tolerance, float function, float axis) { return (smoothstep(function, function + tolerance, axis)) - (smoothstep(function + tolerance, function + 2. * tolerance, axis)); } float derivativeEasingFunction(float minTolerance, float maxTolerance, float maxDerivVal, float derivativeVal) { return ((maxTolerance - minTolerance) * (1. - cos(PI * derivativeVal/ maxDerivVal)) + minTolerance); } void main() { vec2 uv = SCALE * ( 2. * gl_FragCoord.xy/resolution.xy - 1.); uv.x *= resolution.x / resolution.y; // abitrarily chosen to look nice float minEpsilon = 0.03; float maxEpsilon = 1.6 * minEpsilon; // sin(x) float periodNum = 3.; float amplitude = 1.; float sinusoid = amplitude * sin(periodNum * uv.x - 0.5 * time); float derivativeSinusoid = periodNum * amplitude * cos(periodNum * uv.x - 0.5 * time); float maxDerivSinusoid = periodNum * amplitude; // e^-x float exponential = exp(-uv.x); float derivativeExponential = -exp(-uv.x); float maxDerivExponential = -exp(0.73); // chosen with helper line -- max visible f(x) // smin float kk = 0.5; float dd = sinusoid - exponential; float ll = clamp(0.5 + dd / (2. * kk), 0.0, 1.0 ); float dlldx = clamp((derivativeSinusoid - derivativeExponential)/ (2. * kk), 0.0, 1.0 ); float leSmin = (1. - ll) * sinusoid + ll * exponential - kk * ll * (1.0 - ll); float derivativeXi = dlldx * (-dd) + derivativeSinusoid * (1. - ll) + derivativeExponential * ll - dlldx * kk + dlldx * 2. * kk * ll; float derivativeLeSmin = derivativeXi * when_gt(dd, -kk) + derivativeSinusoid * when_le(dd, -kk); // mask for background and making things lighter float mask = length(0.2 * uv); vec3 col = (1. - mask) * vec3(.129, .141, .176); // graphs float graphLeSmin = graph(derivativeEasingFunction(minEpsilon, maxEpsilon, maxDerivSinusoid, derivativeLeSmin), leSmin, uv.y); float graphSinusoid = graph(derivativeEasingFunction(minEpsilon, maxEpsilon, maxDerivSinusoid, derivativeSinusoid), sinusoid, uv.y); float graphExponential = graph(derivativeEasingFunction(minEpsilon, maxEpsilon, maxDerivExponential, derivativeExponential), exponential, uv.y); // making "draw order" graphSinusoid *= (.6 - graphLeSmin); graphExponential *= (.5 - graphSinusoid) * (1. - graphLeSmin); // col and frag col += vec3(0., 0., 1.) * graphSinusoid + vec3(1., 0., 0.) * graphExponential + vec3(0., 1., 0.) * graphLeSmin; fragColor = vec4(col,1.0); }